麻雀における実力と運の同時評価
文責 オグンツ
どこにも麻雀の運や実力が定義されていないので、優秀なフリーAIやシミュレーション環境が整う前に、記事にしておく.
問題は運と実力を同時に評価する手法が確立されていないことにある.
結論
着順ハッシュと実力行列の更新の考えを導入することで,実力と運を同時に評価することが可能である.
同じ実力を持つ者がN回の半荘戦を行うとする.
このときの着順分布は全て”運”によって定まるはずである.
なぜなら着順は運と実力の2要因で決定し,同じ実力(同じ河,牌姿で同じ打牌選択を行う)ならば,
残るは運と呼ばれる要因によってのみ決定し得るからである.
運とは
・ラスハッシュとは
本節の仮定は
「同実力であればラスになる牌山コード群が存在する」
と言い換えられる.
これを今回,md5ハッシュ値を用いていることからラスハッシュと呼称しよう.
さてこのラスハッシュを引く確率は定義から
に確率収束する.
よってラスハッシュの回数,半荘数を
とするとその確率分布は,
となる.(二項分布)
こちらをプログラムしよう.
import math import numpy as np #パラメータ定義 N = 500#半荘数 last_p = float(0.25) #ラス確率 #組み合わせ関数 def combinations_count(n, r): return math.factorial(n) // (math.factorial(n - r) * math.factorial(r)) # log(n!)を求める関数 def ln_fact(n): sum = 0 for i in np.arange(1, n+1, 1): sum += np.log(i) return sum #半荘数Nに対してラスの数nとなる確率 def last_per(N,n): return np.exp((N*np.log(last_p) + (N-n)*np.log(4-1) + ln_fact(N) - ln_fact(N-n) - ln_fact(n)))
・コーディングのお話
--------簡単にアルゴリズムの数式解説(自分用)--------
簡単に作成した関数について説明する.
コンビネーションやn乗を使うのでintやfloatに配分されているbit数を越えるとオーバーフローになる.
そこで
を用いて両辺対数を取って計算する.
に注意しながら,
ここでとすれば上記コードで計算できる.
・ラスハッシュの分布
それでは確率密度関数を導こう.
import numpy as np import matplotlib.pyplot as plt #各種パラメータ設定,改めて定義 N = 1000#半荘数 min_per = 0.1#最低ラスハッシュ率 max_per = 0.4#最高ラスハッシュ率 x = np.empty(0) for i in range(int(N*min_per),int(N*max_per)): x = np.append(x, last_per(N,i)) y = list(np.arange(N*min_per, N *max_per)) plt.plot(y,x)
グラフを見やすくするためにmin_perやmax_perは決めてもらえれば良い.
こちらは離散的な値であることに留意したい.
試行回数Nを増やすことで直ちに正規分布へと近似することはせず,分かりやすくΣで計算しよう.
・尤度
面積を求めることでどれくらい自分がラスハッシュをもらっているのかを定量的に評価できる.
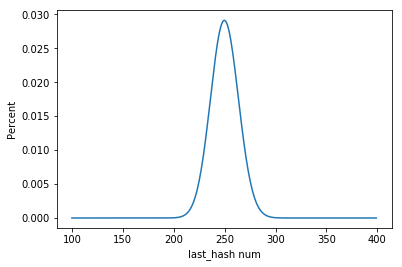
import numpy as np import matplotlib.pyplot as plt #各種パラメータ設定 N = 500#半荘数 min_per = 0#最低ラスハッシュ率 max_per = 1#最高ラスハッシュ率 x = np.empty(0) for i in range(int(N*min_per),int(N*max_per)): x = np.append(x, last_per(N,i)) y = list(np.arange(N*min_per, N *max_per)) plt.xlabel("last_hash num") plt.ylabel("Percent") plt.plot(y,x)

自分のラスハッシュ率が仮に28%である場合,
(ここが今回の議論の核となるが一旦仮定する)
#面積計算 sum=0 real_per = 0.28#ラスハッシュ率 for i in range(int(N*real_per - N*min_per)): sum += x[i] print(sum) #0.9315764131329188
となり,500回打ってラスハッシュ率が28%(500*0.28 = 140)であるとき,
全体の7%くらいの人がそれ以上のラスハッシュをもらっていると言えます.
割合でいうと当然確率収束していくわけですが,実際の上40%と下40%の回数の差は大きくなります.
(今回はラスを取れば取るほど上側になります)

これはこれで残念なことに間違ってるんよな〜
— chanpuku (@Chanpukin) 2021年12月18日
コイントス100回勝負を大勢でしたら、全員が50回前後で同じくらい表が出る訳じゃなくて、30回くらいの人、70回くらいの人も現れる。
回数を増やして長期勝負にすればするほど、集団の中でツイてる人とツイてない人の差はどんどん大きくなっていく。 https://t.co/YQirypHK1l
chanpukuさんのご指摘はNを増やすことで割合の差は小さくなりますが,実際の回数は広がってしまうということかと察します.
なお逆正弦法則とは全く話が違います.(あちらの方は数学としてより高度です💦)
そろそろ察してもらえると思うのですが,こうやってΣで面積を計算するのはかったるいです.
従って二項分布を正規分布に近似して尤度関数を求めるやり方が一般的です.
実力とは
実力行列の定義
さて本題です.上記のような2項分布を多項分布に拡張するだけです.
再び定義します.
すなわち実力とは「与えられた着順ハッシュとは異なる着順になる回数」と定義します.
これは高々4*4=16通りのパターンしかありません.


実験手順
実験の手順としては牌山コードと着順のデータを用意します. 同実力(こちらも実力分布を作っても良いかもしれません)のAIに当該の牌山コードで対戦してもらい,着順ハッシュを算出. その着順ハッシュと実際の着順データを比べ,行列内の確率を更新していきます. このように実力行列Aを考えることで,主成分分析などでの解析もすぐさま可能です.
参考文献(Reference)
参考までにこれまでの麻雀での実力を評価(あるいは実力を利用)しようとした試みを紹介しておく.
どれも素晴らしい着眼点だと思う.
科学する麻雀(とつげき東北, 2004)以降,麻雀を計算的に扱うことの重要性が高まり,放銃率・和了率といったスタッツの可視化が進んでいる.
Yuki[1]はそれらスタッツを主成分分析から予想安定Rというものを
予想安定レート推定値 =1,976 + 762 × ln和了率 + 0.111 × 和了素点 - 348 × ln放銃率 + 186 × ln副露率
を考案している.
たとえば本手法では過剰な副露が推奨されることになり,また各スタッツの収束が評価できていない(運の要素が評価できない).
これまで自分は和了率和了打点 - 放銃率放銃打点や局収支といった値が,真平均着順と相関があることを示してきた.
しかし和了率や放銃率の収束がいかに平均着順や平均期待pt・安定段位より早いとは言え,その確率密度を考慮できていなかった.
このように運を定量化していない点はchanpuku[2]にも表れており,反対にみーにん[3]は運のみを考慮した平均着順のブレを導出している.
逆に全く運を考慮しない手法として久米ら[4]の手法があり,最強AIの選択との誤差で評価している.
これは近年NAGAなどの登場により注目される手法であると共に,AIが正解であることの社会的同意の無さが課題となる.
よって運と実力を同時に評価する手法はこれまで存在せず,本提案が麻雀界の発展に寄与できるものと考える.
[1]Yuki, ネット麻雀「天鳳」を統計的に分析してみた(前編), (2016) アクチュアリーはデータサイエンスの夢を見るか?
[2]chanpuku, ルールによる実力の出やすさの違い, (2021) note.com
[3]みーにん, 麻雀における平均順位のぶれ, (2018) 麻雀における平均順位のぶれ|みーにん|note
[4]久米 洋輝 , 少ない行動記録から麻雀プレイヤの実力を推定する研究, (2018)
実験協力お願い
本仮説は実証実験をすることで初めて検証されます.
このためにはNAGAクラスのAIをはじめ,各種レベル帯に合わせたCPUを用意する必要があります.
またAIが何千という試合を行える環境も必要です.
特にAIの方はフリー素材だとあこちゃんくらいのレベルしか難しいですが,
強化学習の手法とあるので一稼ぎ終わった後くらいにはモデルも公開されると思います.
自分が強いと感じる方の牌譜だけを読み込ませれば,「ボクが考えた最強のえーあい」も作れそうです.